Since as young as I can remember, I’ve cared a lot aboutprivacy andsecurity and have always wanted a search engine that does, while giving me complete control over the results page by letting me write code (or some other syntax) to filter with extreme precision.
I’ve held off on releasing this post until we had a name, but I’m proud to announce Aragoniteα which is our attempt to build a search engine with the quality of 2010s Google and the intelligence of WolframAlpha, plus a syntax that feels like writing code.
Why a new engine?
Google is full of ads, SEO spam, listicles, and has a bias problem. WolframAlpha doesn’t let you see webpages, only facts. I and others at dkwc.org wanted an engine with the intelligence of WolframAlpha that also had the ability to search the web.
What’s unique?
We’ve got a variety of features that make our engine unique
Designed for privacy
We put a huge emphasis on privacy and do not track the user or attempt to associate their queries with any identifiers like an IP or cookie. Both our clearnet and Tor mirrors run all logic on the backend, meaning no JavaScript or WASM on the frontend. The entire search engine has been designed with the idea that someday we may get a subpoena, and we want to confidently tell the lawyers that we collect only the absolute minimum required to operate and we don’t even store it on disk (memory-only).
We see no reason for Google, Bing, or others to store every search you make over the entire history of your account, unless they’re selling it to the CIA or something. Spooky!
Programmatic search
We have a syntax that allows programmers and data scientists to utilize the full power of our engine. The syntax itself feels like writing code with hints of natural language. A search for category:news in language:spanish about bridges will return news in Spanish about bridges, and nothing else. Using in and about is the “proper” way to do it, but our engine is also smart enough to figure out that the intent is the same if you were to type category:news language:spanish bridges.
The syntax supports + (mandatory inclusion), - (mandatory exclusion), and, or, and a wide variety of other operations, which are also compatible with our full schema. +subject_type:privacy -category:reddit messaging apps will force-include results with privacy in the subject_type and force-exclude results where the category is reddit for the query messaging apps.
Database
The database itself is also completely custom, and is somewhat similar to NoSQL without the SQL. In fact, we don’t utilize SQL or anything similar which greatly increases speed and security. I won’t share exactly how it works, but it’s two-stage and read-only which cuts down on the potential for security vulnerabilities, particularly injections.
Index and datasets
We maintain a 100% sovereign index, meaning we do not rely on indexes from other companies. Aragoniteα is independent and can even be operated on airgapped networks with zero external connections.
Our datasets are also entirely our own. We don’t use external data sources due to licensing and a lack of need, everything our engine knows is owned by us.
Dark web indexing
This whole project was started because someone I know wanted to be able to search the dark web. I spent the next three days pulling all-nighters to build a basic search engine that can search the dark web. That data is still in the datasets, and we also show the word “Onion” to the left of regular URLs when the engine detected an equivalent hidden service.
Speed
Did I mention it’s super fast? I’m talkin’ average <20ms per query including query parsing, syntax analysis, formatting, and queueing for HTML generation. Results pages are guaranteed to be under 256kb and are typically under 128kb in size. We’re part of the 512kb club!Take that, Google!
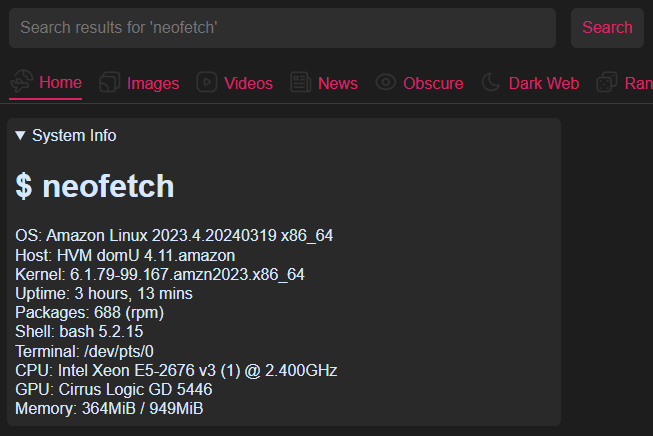
Lightweight
The engine and everything else needed to deliver the same experience that we offer on the cloud hosted version runs nice and fast in under 1gb of ram on an AWS t2.micro instance. Don’t believe me? Type neofetch into the search box and expand the System Info box. You’ll see the real output of neofetch from the host for yourself!
Not AI
During my market research, I discovered that People don’t really want AI and our product has absolutely no user-facing artificial intelligence, and we intend to keep it that way. We rely on having a well designed, Turing complete syntax that feels like programming to deliver quality results instead of using a biased AI that we can’t control. Shoving AI into everything is trendy, but its also stupid. Take that, Microsoft!
Tor compatible
Our engine is compatible with Tor’s strictest settings, and we offer an official hidden service for those who require extra privacy or don’t trust our claim about not logging IPs.
No censorship
Being a programmatic search engine, we do not censor anything. You get what you search for. If you want to hide or show a specific keyword, try putting + or - directly in front of it without a space. See the section on Programmatic search for more info. Safe spaces are stupid.
Mirrors and proxies
We offer mirrors from a variety of public clouds and residential hosts. If a country censors our engine because we don’t do regional censorship (looking at you, Germany) we’ll just deploy more mirrors and proxies to evade the censorship, similar to what Telegram does. Germany will try to censor us for refusing to censor neo-nazi content. A little hypocritical, eh?
Things to note
Business model
We haven’t figured it out yet. We’ve been using organizational savings to pay for things like our AWS bills and domains. Maybe an enterprise or government would like a managed, airgapped instance like what WolframAlpha offers?
We’d prefer not to run ads, but if we need to, we’ll keep them text-only, and keep them far away from the search results, in the bottom right corner of the screen. If we do end up running ads, it means nothing else worked out, but we will not sell you out, and our ads would not track anything beyond an anonymous click counter that just counts up when someone clicks an ad.
License
Everything except for the HTML and CSS is proprietary. I’ve had bad experiences with people taking my open source work and giving nothing back in the past, and I will not let us repeat that mistake. Don’t ask for the source code, you won’t get it.
Credential
I know some people will ask what credentials I have to be building a programmatic search engine from scratch. I don’t have a college degree, but I’ve built many many many many search engines before from scratch. College doesn’t teach you practical things, they take your money and teach you algorithms that you’ll never use in production. Take that, LeetCode pussies!
Conclusion
As you can see, we’ve put a lot of time into this project. I personally have been working on the project sun-up to sun-down with few breaks for the past month, and others have been doing similar amounts of work.
We’re building a search engine that we and others want to see, based on market research and a desire for something that doesn’t sell our data or show us ads and SEO listicle junk.
I hope you’ll check back and see what new things we’re working on, since we’re just getting started and there’s a lot to work on. Next feature will be solving complex math in the search box. (Think: factorials, nested fractions, volume of a sphere, and of course simple math too)